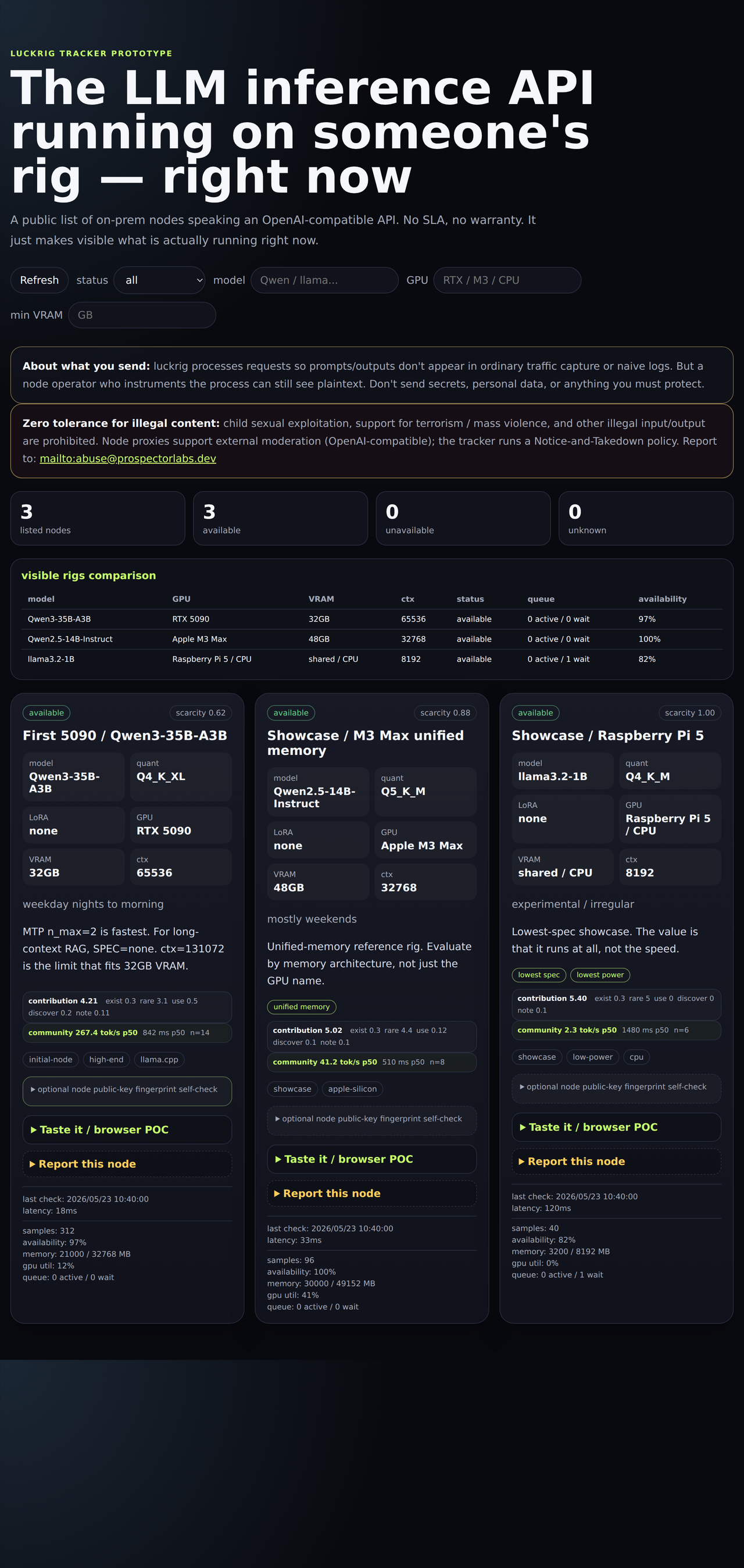
● available scarcity 0.62
first-5090-qwen3
- model
- Qwen3-35B-A3B
- quant
- Q4_K_XL
- GPU
- RTX 5090
- ctx
- 65 536
- VRAM
- 32 GB
- LoRA
- —
MTP n_max=2 is fastest. For long-context RAG, prefer SPEC=none. ctx=131072 is the VRAM ceiling here.
initial-nodehigh-endllama.cpp
community 267.4 tok/s p50 TTFT 842 ms
node fingerprint
sha256:aZuK8JLDYROmCqe8y7_gianXYuAgdIUabuGpFa72aWc